 Před nedávnem se objevila v Lidových novinách v sekci Věda zpráva s názvem Nejlepší překladatel se opičí o tom, že kvalita strojového překladu se zase o kousek přiblížila tomu dobře provedenému lidskému. Což o to, podobné zprávy o novinkách ze světa vědy se v tisku objevují poměrně často. Jejich problém ale spočívá především ve skutečnosti, že v mnoha případech se jedná o přejaté zprávy o zprávách (o jiných zprávách atd.). Výsledkem pak mnohdy bývá, že informační hodnota takového článku je kvůli velkému zjednodušení buď velmi nízká nebo i zavádějící. S danou zprávou je to ale v určitém ohledu trochu jiné. Zaujala mě především díky dvěma úzce souvisejícím faktům: za prvé se v ní operuje s termínem, který může nepoučeným konotovat představy, které nejsou úplně přesné (přestože je užití tohoto termínu z technického hlediska korektní a náležité!), za druhé se tu možná implicitně říká něco o jazyce a řeči obecně, tj. nejen z hlediska jejich počítačového zpracování, běžnému smrtelníkovi i tak dost vzdáleného. O co tedy jde.
Před nedávnem se objevila v Lidových novinách v sekci Věda zpráva s názvem Nejlepší překladatel se opičí o tom, že kvalita strojového překladu se zase o kousek přiblížila tomu dobře provedenému lidskému. Což o to, podobné zprávy o novinkách ze světa vědy se v tisku objevují poměrně často. Jejich problém ale spočívá především ve skutečnosti, že v mnoha případech se jedná o přejaté zprávy o zprávách (o jiných zprávách atd.). Výsledkem pak mnohdy bývá, že informační hodnota takového článku je kvůli velkému zjednodušení buď velmi nízká nebo i zavádějící. S danou zprávou je to ale v určitém ohledu trochu jiné. Zaujala mě především díky dvěma úzce souvisejícím faktům: za prvé se v ní operuje s termínem, který může nepoučeným konotovat představy, které nejsou úplně přesné (přestože je užití tohoto termínu z technického hlediska korektní a náležité!), za druhé se tu možná implicitně říká něco o jazyce a řeči obecně, tj. nejen z hlediska jejich počítačového zpracování, běžnému smrtelníkovi i tak dost vzdáleného. O co tedy jde.I letos vyhlásila agentura DARPA (což je mimochodem zkratka pro The Defense Advanced Research Projects Agency, tj. agenturu ministerstva obrany USA, která má na starosti vědecký výzkum aplikovatelný v oblasti vojenství) soutěž o nejlepší program strojového překladu textů. Není to v žádném případě poprvé, kdy je de facto lingvistický projekt financován ze zdrojů určených na obranu a vojenský výzkum. Klasickým příkladem jsou například slavné Chomského Syntaktické struktury, které financovaly organizace americkým letectvem počínaje a námořnictvem konče. Oblast počítačového zpracování jazyka a automatizovaného překladu je totiž už od počátku svého vývoje mimořádně pečlivě sledována právě vojenskými kruhy a v dnešní době je k ní opět obracena pozornost v souvislosti s fenoménem terorismu. Počátky strojového překladu, které můžeme datovat již do prvních roků padesátých let dvacátého století, totiž zcela nepochybně souvisely s tzv. studenou válkou a tehdejším vědecko-technickým soupeřením světových mocností.
Na vlastním výzkumu možností strojového překladu se záhy začalo pracovat i v tehdejším Československu. Z lingvistů se na něm podílela především skupina organizovaná kolem Petra Sgalla, osobnosti, která je v české lingvistice téměř synonymem pro algebraickou jazykovědu. V průběhu téměř padesáti let dosáhl tento tým (J. Panevová, E. Hajičová, E. Buráňová, S. Machová atd. atd.) mnoha úspěchů a uznání nejen v kontextu domácím - kde vlastně ani nebylo možné hovořit o nějaké alternativě - ale i v zahraničí. Přes všechny obrovské naděje, které byly v počátcích strojové lingvistiky do tohoto oboru vkládány, a o to větší pády, jež po vystřízlivění z těchto představ následovaly, se podařilo výzkum na tomto poli u nás nejen zachovat, ale i rozvinout a vybudovat tak silnou tradici, která je nesena několika významnými pracovišti, jako jsou například Ústav teoretické a komputační lingvistiky, Ústav formální a aplikované lingvistiky nebo Ústav českého národního korpusu.
Přestože zájem o strojovou lingvistiku byl motivován především praktickými cíli, je tato oblast mimořádně zajímavá z hlediska teoretické jazykovědy. Pokus zpracovat systém jazyka formálně za pomoci matematicko-informatických metod položil před jazykovědce ohromnou výzvu. V duchu Chomského návrhů je možné říct, že přišla chvíle, kdy lingvisté museli při popisu jazyka explicitně vyjádřit mnohé z toho, co bylo předpokládáno jako samozřejmé, že museli jasně a schematicky formulovat základní strukturní vlastnosti jazyků a soubory pravidel, o něž se může následná produkce řeči opřít - to všechno samozřejmě ve smyslu modelů "černé skříňky" a s omezením na to, co Chomsky definoval jako jazykovou kompetenci. Později, v souvislosti s tzv. pragmatickým nebo také komunikačním obratem v jazykovědě, se pochopitelně začal zájem části lingvistů modelujících jazykovou kompetenci pomocí matematických nástrojů obracet i k problémům spjatým s jeho užíváním, což byl jeden z procesů, který pomáhal formovat mosty k transdisciplinárním zkoumáním v rámci kognitivní vědy.
Z obecného hlediska je důležité především to, že v pozadí těchto snah stojí samozřejmě implicitně úvaha, co přesně je těmito postupy modelováno a jaké nároky, případně předpoklady adekvátnosti na tyto modely klást. Můžeme si například položit otázku, do jaké míry pouze vytváříme algoritmická schémata, která na základě požadavku co největší efektivity a mohutnosti dokáží analyzovat lineární vstup v podobě jazykového kódu a pomocí implementovaných "rozhodovacích" procedur je desambiguovat, vytvořit významový "zápis" v jazyce sloužícím jako terra comparationis a syntetizovat jej do jazyka cílového, a do jaké míry modelujeme chování lidského překladatele. Od chvíle, kdy Chomsky před téměř padesáti lety vyhlásil svůj program jako snahu o integraci lingvistiky s kognitivní psychologií, se odpovědi různí...
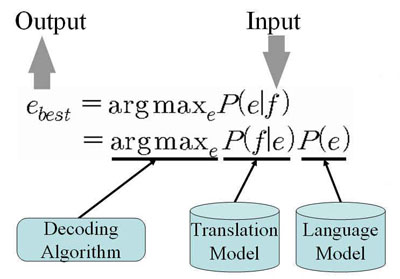
S touto problematikou souvisí právě otázky vztahující se k již zmiňovanému článku. V tom se totiž tvrdí, že "do praxe totiž míří nová generace programů, která se nezatěžuje větným rozborem, ale sází na hrubou sílu a velké slovníky vzorových textů". To je tvrzení přinejmenším nepřesné a zároveň i nechtěně zavádějící. Z textu se bohužel nedozvíme podrobněji, jak celý proces funguje, zjistíme jen, že "princip je jednoduchý: program na začátku o cizím jazyce „neví“ nic. Ale dostane k dispozici velké množství textů ve zdrojovém a v cílovém jazyce a pak si v nich sám najde pravidla. Například v případě překladu z arabštiny do angličtiny stroj opakovaně srovnává řetězce textu v arabštině s jejich anglickými protějšky a postupně vytvoří hrubý překlad. Následně text vyladí s využitím vzorů „odkoukaných“ z učebních anglických textů, čímž napodobí slovosled přirozeného jazyka. Není potřeba programovat algoritmy simulující gramatická pravidla, což je velmi náročné, málo efektivní a hlavně - musí se vytvářet pro každý jazyk zvlášť". To je ale nejen těžko pochopitelné, ale zamlčuje to jisté předpoklady.
Tvrzení, že "program na začátku o cizím jazyce „neví“ nic" by bylo nutné asi poopravit v tom smyslu, že program neobsahuje sice žádnou konkrétní implementaci gramatických pravidel daných jazyků, ale nejspíš procedury, jak taková pravidla vytvářet (ve smyslu "nacházet" v textu data a na jejich základě je generovat). To znamená, že počítač není lockovská tabula rasa, ale obsahuje algoritmy pro tvorbu pravidel na základě statistických dat. Ty defacto modelují kognitivní bázi pro zpracovávání jistého typu informací. Vytváří statistické korelace na základě srovnání textů z paralelních korpusů. Vybaven těmito statistickými korelacemi (charakteristickými zřejmě v této fázi pro určitý omezený typ textů, ale potenciálně využitelný i mimo rámec jejich okruhu) poté přistupuje k neznámému textu ve zdrojovém jazyce a pokouší se vytvořit jeho zobrazení v jazyce cílovém. Jen takto dokážu rozumět tvrzení, že "například v případě překladu z arabštiny do angličtiny stroj opakovaně srovnává řetězce textu v arabštině s jejich anglickými protějšky a postupně vytvoří hrubý překlad". Program se tedy opírá o zákonitosti formulované v teorii informace a na jejich základě analyzuje zdrojový text a generuje text cílový. Poznámku o vylaďování slovosledu, které se v případě statisticky zpracovávaného překlad opravdu užívá, by asi bylo vhodné také upřesnit, protože slovosled není v mnoha jazycích záležitostí libovolnou, ale je součástí jazykových pravidel, tedy nikoliv pouze otázkou stylistickou. (Ani čeština není - na rozdíl od toho, co se obvykle tvrdí - v otázce slovosledu absolutně bez omezení: i zde má slovosled sémanticko-gramatickou distinktivní funkci.)
V čem má zmiňovaný článek naprostou pravdu, je tvrzení, že klasický algoritmizovaný překlad postavený na implementaci jazykové struktury ve formě pravidel (rule-based či transfer-based machine translation) je jednak mimořádně náročný, jednak je nutné zpracovávat jej pro každý jazyk zvlášť. Není přitom nutné zpracovávat převodní pravidla vždy pro dvojici jazyků, ale pouze ve vztahu k jazyku převodnímu, který by měl představovat univerzální reprezentaci daných vět. Nutné je ale dodat, že i odborníci věnující se tomuto typu strojového překladu uznávají, že v mnoha případech je ideální kombinovat tuto metodu právě s metodou statistickou.
Obrovská výhoda statistického strojového překladu je v jeho relativně univerzální použitelnosti, snazší přípravě, ale například i ve schopnosti poradit si s jevy známými z teorie komunikace, jako je přítomnost šumu apod. Zatímco detaily jsou už otázkou pro odborníky, je možné zamyslet se nad obecnou otázkou nechtěně položenou v úvodu komentovaného článku: je výraz hrubá síla vhodný pro charakteristiku takového typu překladu? Nejprve je třeba říct, že se jedná o termín běžně užívaný v informatice a má charakterizovat taková řešení, která se opírají o velké datové databáze, tj. ne o implementaci hotových pravidel. Je pravdou, že takový překlad je také možné chápat jako primárně formální nebo čistě syntaktický v širokém smyslu slova - hledá se korelace ve smyslu substituce elementu za element na základě jejich formy, případně kontextového okolí. Takový přístup nebuduje něco jako sémantickou bázi, pracuje s pravděpodobností výskytu apod. Je omezen stanoveným korpusem, ze kterého se program "učí". Potud je konotace výrazu hrubá síla nejspíš správná. Vzato ale ze druhé strany - významem slova je dle Wittgensteina, vlivného filosofa jazyka, způsob jeho užívání v jazykových hrách, tj. znát význam znamená náležitě užívat jazykové výrazy - adekvátně situaci. Evidence je čistě behaviorální - pokud je jazykový výraz "tam, kde má být", mluvčí jej použil správně - ve shodě s jeho významem. Počítačový program, který produkuje texty, jež jsou v tomto smyslu adekvátní, ovládá v jistém slova smyslu určité aspekty významu jazykových výrazů. A tu se nám může vynořit z hloubek jazyka otázka: nejsou statistické metody - úspěšně aplikované ve výzkumu překladu - při vysvětlování principů učení se jazyku (čili v jistém ohledu schopnosti smysluplné komunikace v určité skupině, de Saussurovy langage) vhodnějším východiskem než představa o vrozené univerzální gramatice. Nejsou experimenty s trénováním umělých neuronových sítí a jejich zatím skromné, ale přesto nadějné výsledky pobídkou k cestě tímto směrem? A není spojení "hrubá síla" právě proto tak symptomaticky dvojznačné?...
Mnozí si to nemyslí a uvádějí pro to pádné důvody. O tom ale až příště.
Na vlastním výzkumu možností strojového překladu se záhy začalo pracovat i v tehdejším Československu. Z lingvistů se na něm podílela především skupina organizovaná kolem Petra Sgalla, osobnosti, která je v české lingvistice téměř synonymem pro algebraickou jazykovědu. V průběhu téměř padesáti let dosáhl tento tým (J. Panevová, E. Hajičová, E. Buráňová, S. Machová atd. atd.) mnoha úspěchů a uznání nejen v kontextu domácím - kde vlastně ani nebylo možné hovořit o nějaké alternativě - ale i v zahraničí. Přes všechny obrovské naděje, které byly v počátcích strojové lingvistiky do tohoto oboru vkládány, a o to větší pády, jež po vystřízlivění z těchto představ následovaly, se podařilo výzkum na tomto poli u nás nejen zachovat, ale i rozvinout a vybudovat tak silnou tradici, která je nesena několika významnými pracovišti, jako jsou například Ústav teoretické a komputační lingvistiky, Ústav formální a aplikované lingvistiky nebo Ústav českého národního korpusu.
Přestože zájem o strojovou lingvistiku byl motivován především praktickými cíli, je tato oblast mimořádně zajímavá z hlediska teoretické jazykovědy. Pokus zpracovat systém jazyka formálně za pomoci matematicko-informatických metod položil před jazykovědce ohromnou výzvu. V duchu Chomského návrhů je možné říct, že přišla chvíle, kdy lingvisté museli při popisu jazyka explicitně vyjádřit mnohé z toho, co bylo předpokládáno jako samozřejmé, že museli jasně a schematicky formulovat základní strukturní vlastnosti jazyků a soubory pravidel, o něž se může následná produkce řeči opřít - to všechno samozřejmě ve smyslu modelů "černé skříňky" a s omezením na to, co Chomsky definoval jako jazykovou kompetenci. Později, v souvislosti s tzv. pragmatickým nebo také komunikačním obratem v jazykovědě, se pochopitelně začal zájem části lingvistů modelujících jazykovou kompetenci pomocí matematických nástrojů obracet i k problémům spjatým s jeho užíváním, což byl jeden z procesů, který pomáhal formovat mosty k transdisciplinárním zkoumáním v rámci kognitivní vědy.
Z obecného hlediska je důležité především to, že v pozadí těchto snah stojí samozřejmě implicitně úvaha, co přesně je těmito postupy modelováno a jaké nároky, případně předpoklady adekvátnosti na tyto modely klást. Můžeme si například položit otázku, do jaké míry pouze vytváříme algoritmická schémata, která na základě požadavku co největší efektivity a mohutnosti dokáží analyzovat lineární vstup v podobě jazykového kódu a pomocí implementovaných "rozhodovacích" procedur je desambiguovat, vytvořit významový "zápis" v jazyce sloužícím jako terra comparationis a syntetizovat jej do jazyka cílového, a do jaké míry modelujeme chování lidského překladatele. Od chvíle, kdy Chomsky před téměř padesáti lety vyhlásil svůj program jako snahu o integraci lingvistiky s kognitivní psychologií, se odpovědi různí...
S touto problematikou souvisí právě otázky vztahující se k již zmiňovanému článku. V tom se totiž tvrdí, že "do praxe totiž míří nová generace programů, která se nezatěžuje větným rozborem, ale sází na hrubou sílu a velké slovníky vzorových textů". To je tvrzení přinejmenším nepřesné a zároveň i nechtěně zavádějící. Z textu se bohužel nedozvíme podrobněji, jak celý proces funguje, zjistíme jen, že "princip je jednoduchý: program na začátku o cizím jazyce „neví“ nic. Ale dostane k dispozici velké množství textů ve zdrojovém a v cílovém jazyce a pak si v nich sám najde pravidla. Například v případě překladu z arabštiny do angličtiny stroj opakovaně srovnává řetězce textu v arabštině s jejich anglickými protějšky a postupně vytvoří hrubý překlad. Následně text vyladí s využitím vzorů „odkoukaných“ z učebních anglických textů, čímž napodobí slovosled přirozeného jazyka. Není potřeba programovat algoritmy simulující gramatická pravidla, což je velmi náročné, málo efektivní a hlavně - musí se vytvářet pro každý jazyk zvlášť". To je ale nejen těžko pochopitelné, ale zamlčuje to jisté předpoklady.
Tvrzení, že "program na začátku o cizím jazyce „neví“ nic" by bylo nutné asi poopravit v tom smyslu, že program neobsahuje sice žádnou konkrétní implementaci gramatických pravidel daných jazyků, ale nejspíš procedury, jak taková pravidla vytvářet (ve smyslu "nacházet" v textu data a na jejich základě je generovat). To znamená, že počítač není lockovská tabula rasa, ale obsahuje algoritmy pro tvorbu pravidel na základě statistických dat. Ty defacto modelují kognitivní bázi pro zpracovávání jistého typu informací. Vytváří statistické korelace na základě srovnání textů z paralelních korpusů. Vybaven těmito statistickými korelacemi (charakteristickými zřejmě v této fázi pro určitý omezený typ textů, ale potenciálně využitelný i mimo rámec jejich okruhu) poté přistupuje k neznámému textu ve zdrojovém jazyce a pokouší se vytvořit jeho zobrazení v jazyce cílovém. Jen takto dokážu rozumět tvrzení, že "například v případě překladu z arabštiny do angličtiny stroj opakovaně srovnává řetězce textu v arabštině s jejich anglickými protějšky a postupně vytvoří hrubý překlad". Program se tedy opírá o zákonitosti formulované v teorii informace a na jejich základě analyzuje zdrojový text a generuje text cílový. Poznámku o vylaďování slovosledu, které se v případě statisticky zpracovávaného překlad opravdu užívá, by asi bylo vhodné také upřesnit, protože slovosled není v mnoha jazycích záležitostí libovolnou, ale je součástí jazykových pravidel, tedy nikoliv pouze otázkou stylistickou. (Ani čeština není - na rozdíl od toho, co se obvykle tvrdí - v otázce slovosledu absolutně bez omezení: i zde má slovosled sémanticko-gramatickou distinktivní funkci.)
V čem má zmiňovaný článek naprostou pravdu, je tvrzení, že klasický algoritmizovaný překlad postavený na implementaci jazykové struktury ve formě pravidel (rule-based či transfer-based machine translation) je jednak mimořádně náročný, jednak je nutné zpracovávat jej pro každý jazyk zvlášť. Není přitom nutné zpracovávat převodní pravidla vždy pro dvojici jazyků, ale pouze ve vztahu k jazyku převodnímu, který by měl představovat univerzální reprezentaci daných vět. Nutné je ale dodat, že i odborníci věnující se tomuto typu strojového překladu uznávají, že v mnoha případech je ideální kombinovat tuto metodu právě s metodou statistickou.
Obrovská výhoda statistického strojového překladu je v jeho relativně univerzální použitelnosti, snazší přípravě, ale například i ve schopnosti poradit si s jevy známými z teorie komunikace, jako je přítomnost šumu apod. Zatímco detaily jsou už otázkou pro odborníky, je možné zamyslet se nad obecnou otázkou nechtěně položenou v úvodu komentovaného článku: je výraz hrubá síla vhodný pro charakteristiku takového typu překladu? Nejprve je třeba říct, že se jedná o termín běžně užívaný v informatice a má charakterizovat taková řešení, která se opírají o velké datové databáze, tj. ne o implementaci hotových pravidel. Je pravdou, že takový překlad je také možné chápat jako primárně formální nebo čistě syntaktický v širokém smyslu slova - hledá se korelace ve smyslu substituce elementu za element na základě jejich formy, případně kontextového okolí. Takový přístup nebuduje něco jako sémantickou bázi, pracuje s pravděpodobností výskytu apod. Je omezen stanoveným korpusem, ze kterého se program "učí". Potud je konotace výrazu hrubá síla nejspíš správná. Vzato ale ze druhé strany - významem slova je dle Wittgensteina, vlivného filosofa jazyka, způsob jeho užívání v jazykových hrách, tj. znát význam znamená náležitě užívat jazykové výrazy - adekvátně situaci. Evidence je čistě behaviorální - pokud je jazykový výraz "tam, kde má být", mluvčí jej použil správně - ve shodě s jeho významem. Počítačový program, který produkuje texty, jež jsou v tomto smyslu adekvátní, ovládá v jistém slova smyslu určité aspekty významu jazykových výrazů. A tu se nám může vynořit z hloubek jazyka otázka: nejsou statistické metody - úspěšně aplikované ve výzkumu překladu - při vysvětlování principů učení se jazyku (čili v jistém ohledu schopnosti smysluplné komunikace v určité skupině, de Saussurovy langage) vhodnějším východiskem než představa o vrozené univerzální gramatice. Nejsou experimenty s trénováním umělých neuronových sítí a jejich zatím skromné, ale přesto nadějné výsledky pobídkou k cestě tímto směrem? A není spojení "hrubá síla" právě proto tak symptomaticky dvojznačné?...
Mnozí si to nemyslí a uvádějí pro to pádné důvody. O tom ale až příště.
Žádné komentáře:
Okomentovat